This time we’re having a database where sequences were used, but not systematically as a default value of a given column. It’s mainly an historic bad idea, but you know the usual excuse with bad ideas and bad code: the first 6 months it’s experimental, after that it’s historic.
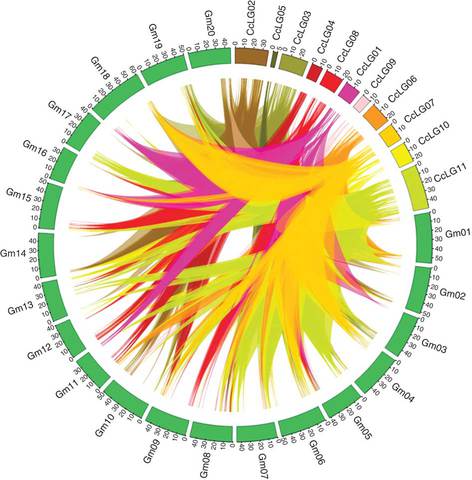
Not talking about genome orphaned sequences here, though
Still, here’s a query for 8.4 that will allow you to list those sequences you have that are not used as a default value in any of your tables: