Queen, Princesses, and Workers
The PostgreSQL community made the explicit choice some times ago that they would not use the infamous master and slave terminology. Instead, the documentation introduces the concepts of High Availability, Load Balancing, and Replication with the terms Primary and Standby, and the even more generic term Replica is used in contexts when only the data flow is considered, rather than the particular role of a node.
Multi-Nodes Architectures and Roles
In current Production Architectures we often have to deal with multi-nodes systems. It always begins with High-Availability concerns: what if my main database server gets hit by a meteorite and is then unable to handle any processing at all?
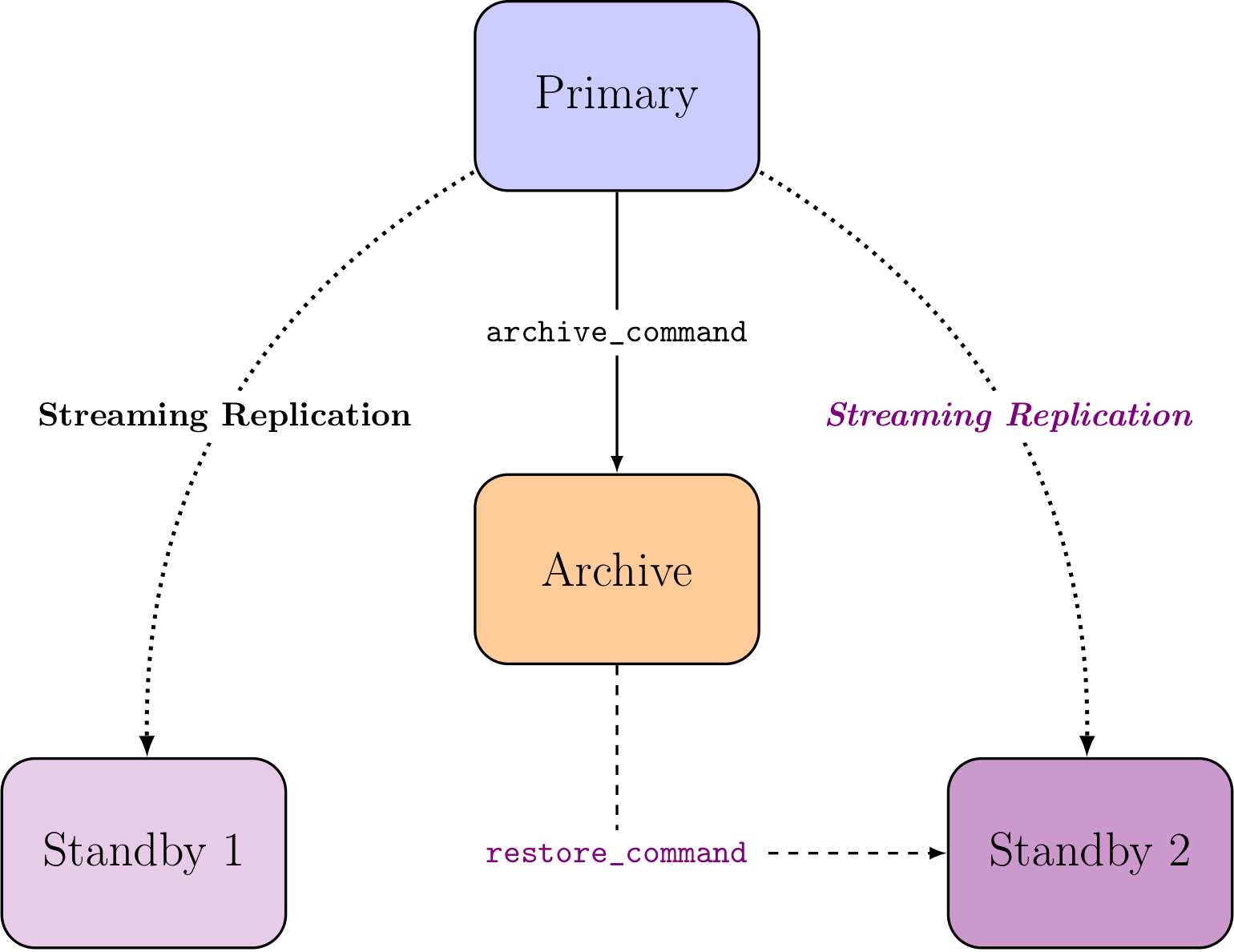
Also, when dealing with a database server, the availability isn’t just about the service. The data is needed too, otherwise we might have to declare bankruptcy. So we need a mecanism to have the data available at all times. The only way to ensure that is by implementing online backups and Point In Time Recovery archiving, when using PostgreSQL. With other data systems, the terminology might be different, the concepts will be the same.
Now with backups and automated recovery in place, in case when our primary PostgreSQL server crashes then the plan is simple:
Get a new PostgreSQL server online.
Run the automated recovery job on this new server.
Open the service again.
The second step here might take quite some time, depending on how much volume needs to be transfered over the network. While the transfering and recovering are happening, the service is unavailable…
High-Availability
In order to reduce the maintenance window at the time when we replace the primary PostgreSQL server, we might want to have a secondary server ready to serve. When using PostgreSQL, it’s as easy as implementing Hot Standby in between two servers, and promoting the standby in case the primary server isn’t available anymore.
Do you know why it’s called Hot-Standby?
That’s because not only the standy server is open to read-only queries, but also at the time when the promotion of the standby to being the new primary occurs, the read-only queries that are currently running aren’t affected by the promotion.
So now we have multiple PostgreSQL nodes in production, or a multi-node architecture, with well defined roles:
The primary server handles all the traffic.
The secondary server replays the write-traffic and is ready to take over the whole production traffic in case we need to halt the primary.
We might have more than one secondary server, even in a cascading setup. Which is very useful in multi-datacenters setup, or multiple Availability Zones cases.
Now, in this setup, every secondary server accepts read-only queries.
Load-Balancing
Having several secondary servers up-to-date or lagging less than a second behind the primary server, it’s tempting to use them for the reporting activities.
One thing leading to another, the secondary servers soon enough receive quite an important read-only traffic:
The nightly batches for business reporting (D-1 and the like).
Those other business exports (for customers, invoicing, finance, etc).
Some end-user traffic that’s know to be read-only.
And then someday the default for the end-user facing production traffic is to hit one of the secondary servers. The primary server is left to deal with only the write traffic, or as close as possible to that.
Hint: when doing write-then-read within the same end-user activity, always do that on the same database connection. That’s the only proper way to avoid data inconsistencies where the correctness of your processing depends on the lag of the secondary systems.
Mixed Architectures
And our production systems implement a Mixed Architecture, where hopefully the role of every part of the system is well known, and clearly labeled. Let’s see about that:
The primary server handles all the writes and is known as the single source of truth of the architecture, both by the operators and the application code.
A couple of secondary servers are used to implement High-Availability and take over on the primary role when this is needed.
A bunch of secondary servers are used to implement Load-Balancing and serve read-only traffic that comes either from background activities (such as mighly batches, exports, and reportings) or directly serving user-facing activities.
Oopsie. I think we have a problem in our choice of terminology now. When dealing with a secondary server, it could either be a primary redundancy or a load-balancing node.
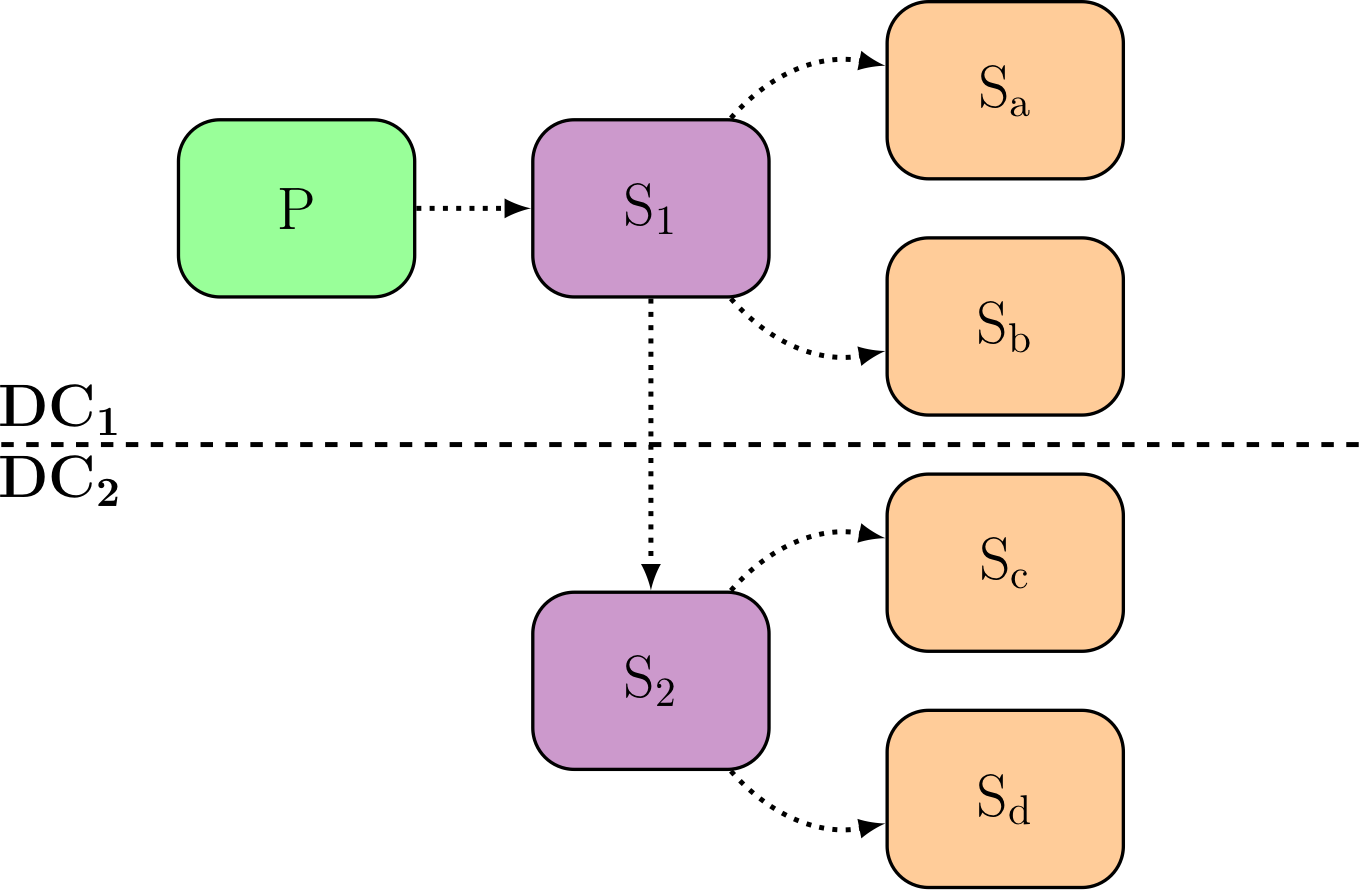
Queen, Princesses, and Workers
My proposal to clarify the situation is to use a well-known terminology, taken from the bees. In a bee hive, we can see different roles that are well defined:
The Queen Bee
In any bee hive, there is a single Queen. Her role is clearly defined (she serves as the reproducer, and that’s it), and only one Bee at a time in the Hive (or colony) is allowed this role.
The princess
In the Queen Bee Wikipedia article, we read:
As the queen ages her pheromone output diminishes. A queen bee that becomes old, or is diseased or failing, is replaced by the workers in a procedure known as “supersedure”.
To replace the Queen Bee you need a special kind of bee, raised in a Queen Cell and fed with Royal Jelly. So when it’s time to supersedure the Queen, the candidates are clearly identified.
In the bee terminology we don’t use the term princess. On the other hand, everyone knows that a Princess is only raised to be a Queen someday. Not that every Princess is going to have the opportunity, mind you.
The Worker Bees
Their role is pretty clear: they do all the work that needs to be done in the hive, except for the role of the Queen, which they assist in several ways.
Conclusion
As a conclusion, I think that the Bee terminology is a better one in for Multi-Nodes Architectures. The goal of a terminology is dual. First, the choice of vocabulary will have an impact on how you think about the world around you, so picking positive and warm-feelings words has an impact. Second, in mixed architectures, it’s important that everybody has a shared understanding of the role of each server:
The Queen is the source of truth and handles all the write traffic.
A Princess is maintained so as to be able to take-over the Queen when needed, usually when it dies or becomes unable to sustain the workload.
Workers do everything else.
Will you use this terminology on your next Architecture diagrams?
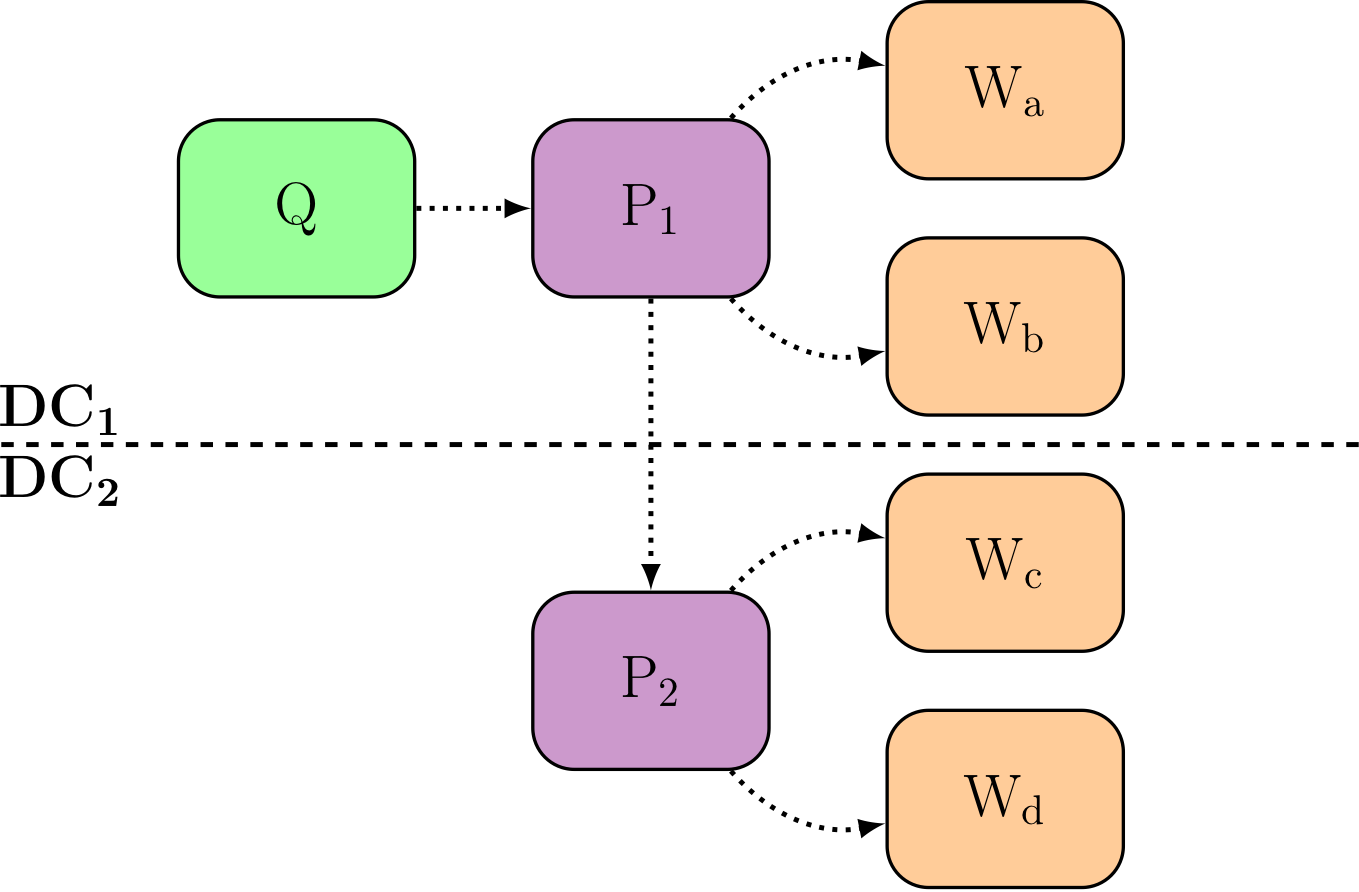
This terminology makes our understanding and expectations clearer. Now it’s easy for everybody to understand that the Queen is expected to be unique in its role, at any time. That the Princess servers are only expected to be able to take-over within as small a maintenance window as possible, in case something happens to the Queen. And finally, the Workers are expected to be doing the heavy work.
