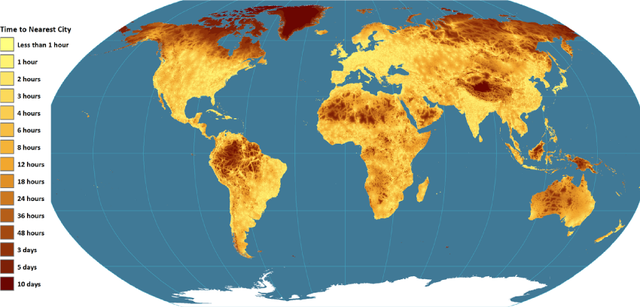
In this article, we want to find the town with the greatest number of inhabitants near a given location.
A very localized example We first need to find and import some data, and I found at the following place a CSV listing of french cities with coordinates and population and some numbers of interest for the exercise here.
To import the data set, we first need a table, then a COPY command: