Batch Update
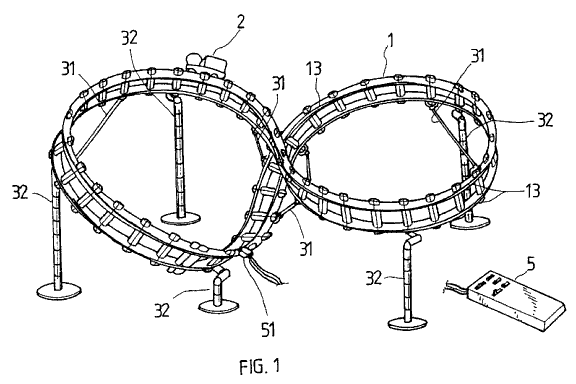
Performance consulting involves some tricks that you have to teach over and over again. One of them is that SQL tends to be so much better at dealing with plenty of rows in a single statement when compared to running as many statements, each one against a single row.
So when you need to
UPDATE a bunch of rows from a given source, remember
that you can actually use a
JOIN in the
update statement. Either the source
of data is already in the database, in which case it’s as simple as using
the
FROM clause in the
update statement, or it’s not, and we’re getting back
to that in a minute.
Update From
It’s all about using that
FROM clause in an
update statement, right?
UPDATE target t
SET counter = t.counter + s.counter,
FROM source s
WHERE t.id = s.id
Using that, you can actually update thousands of rows in our target table in a single statement, and you can’t really get faster than that.
Preparing the Batch
Now, if you happen to have the source data in your application process' memory, the previous bits is not doing you any good, you think. Well, the trick is that pushing your in-memory data into the database and then joining against the now local source of data is generally faster than looping in the application and having to do a whole network round trip per row.
Let’s see how it goes:
CREATE TEMP TABLE source(LIKE target INCLUDING ALL) ON COMMIT DROP;
COPY source FROM STDIN;
UPDATE target t
SET counter = t.counter + s.counter,
FROM source s
WHERE t.id = s.id
As we’re talking about performances, the trick here is to use the
COPY
protocol to fill in the
temporary table we just create to hold our data. So
we’re now sending the whole data set in a temporary location in the
database, then using that as the
UPDATE source. And that’s way faster than
doing a separate
UPDATE statement per row in your batch, even for small
batches.
Also, rather than using the SQL
COPY command, you might want to look up the
docs of the PostgreSQL driver you are currently using in your application,
it certainly includes some higher level facilities to deal with pushing the
data into the streaming protocol.
Insert or Update
And now sometime some of the rows in the batch have to be
updated while some
others are new and must be inserted. How do you do that? Well, PostgreSQL
9.1 brings on the table
WITH support for all
DML queries, which means that
you can do the following just fine:
WITH upd AS (
UPDATE target t
SET counter = t.counter + s.counter,
FROM source s
WHERE t.id = s.id
RETURNING s.id
)
INSERT INTO target(id, counter)
SELECT id, sum(counter)
FROM source s LEFT JOIN upd t USING(id)
WHERE t.id IS NULL
GROUP BY s.id
RETURNING t.id
That query here is updating all the rows that are known in both the target and the source and returns what we took from the source in the operation, so that we can do an anti-join in the next step of the query, where we’re inserting any row that was not taken care of in the update part of the statement.
Note that when the batch gets to bigger size it’s usually better to join
against the
target table in the
INSERT statement, because that will have an
index on the join key.
Concurrency patterns
Now, you will tell me that we just solved the
UPSERT problem. Well what
happens if more than one transaction is trying to do the
WITH (UPDATE) INSERT dance at the same time? It’s a single
statement, so it’s a single
snapshot. What can go wrong?
What happens is that as soon as the concurrent sources contain some data for
the same
primary key, you get a
duplicate key error on the insert. As both
the transactions are concurrent, they are seeing the same
target table where
the new data does not exists, and both will conclude that they need to
INSERT the new data into the
target table.
There are two things that you can do to avoid the problem. The first thing is to make it so that you’re doing only one batch update at any time, by architecting your application around that constraint. That’s the most effective way around the problem, but not the most practical.
The other thing you can do, is force the concurrent transactions to serialize one after the other, using an explicit locking statement:
LOCK TABLE target IN SHARE ROW EXCLUSIVE MODE;
That lock level is not automatically acquired by any PostgreSQL command, so the only way it helps you is when you’re doing that for every transaction you want to serialize. When you know you’re not at risk (that is, when not playing the insert or update dance), you can omit taking that lock.
Conclusion

The SQL language has its quirks, that’s true. It’s been made for efficient data processing, and with recent enough PostgreSQL releases you even have some advanced pipelining facilities included in the language. Properly learning how to make the most out of that old component of your programming stack still makes a lot of sense today!
