Mastering PostgreSQL: a reader's interview
Florent Fourcot has read Mastering PostgreSQL in Application Development and has seen tremendous inprovements in his production setup from reading the first chapters and applying the book advices to his use case.
Here’s an interview run with Florent where he explains the context in which such improvements has been made!
Hi Florent, can you introduce yourself, tell us about your company and explain the role you have there to our readers?
Hi Dimitri. Let’s start with the company. I’m working for Wifirst, an Internet service provider specializing in WiFi deployment and management. Wifirst is the developer of a “WiFi as a Service” hub and other LAN and WAN solutions. We started with student residence halls and now we’re targeting hotels, resorts, campsites, and military bases along with student residence halls, as well as businesses — companies outsourcing WiFi services for our offer “WiFi as a service”, like French Post or the retail sector. For some numbers, today we operate more than 130,000 WiFi access points and 15,000 WAN lines (fiber or DSL). We are not far away from a 100Gb/s download traffic peak, with more than 90% of it peering.
I’m a member of the team developing the box (border router) that we deliver to every customer. We are also working on oversight, automating configuration, and more. For French people, one colleague of mine gave a talk some months ago.
And if you like Python and networking on Linux, we are hiring, see http://www.wifirst.fr/offres/ingenieur-python-et-reseau.
I’m also contributor to OpenSource software. I have been a project leader for several years for the Weboob (http://weboob.org/) project and I love the pyroute2 library (https://github.com/svinota/pyroute2), for example.
What is your main use case for PostgreSQL? In what kinds of situations do you rely on the world’s most advanced open source database?
As I said, my team is in charge of our internal oversight. This administration is built on top of a Django application using PostgreSQL. It’s not a very advanced utilization right now, but it’s still time consuming.
One more advanced usage is our currently in development configuration database. For this use case, we are very happy to be using JSONB columns, lateral joins and other advanced features of PostgreSQL.
Other development teams have bigger use cases, for example storing all user sessions, but I’m not directly involved in this kind of topics.
You bought Mastering PostgreSQL in Application Development, the book I wrote this summer and published last month. What did you expect from the book? Which edition did you select, and why?

First of all, I must admit that I’m not a SQL (or PostgreSQL) expert. Nonetheless my company is generally too small to have a dedicated database administrator. At the same time, we are too big to not think about database scalability and data consistency.
So I had two goals when buying this book: to confirm that our use in already developed applications is not too far away from today’s standards, and second to have a deeper understanding of what is possible with PostgreSQL in order to make the proper decisions in terms of our incoming configuration database.
I chose the Full Edition, since it’s cool to have ready to use examples.
Now on to the meat of this interview. You mentioned on Twitter that you observed some positive impact in production directly after applying some advice from the book, while still reading through the first chapters. Can you tell us more about that?
Yes of course! It was our supervision software. From our point of view, the application was already not too badly optimized. We use advanced Django features, we had relevant indexes, and a deep cleanup was made several years ago. It was not critical to optimize it now, but since our company is growing fast, it was not a waste of time to have a look at it.
When I checked our code, it was rather nice to have a practical use case from the book. The first tip on pg_stat_statement made a big difference, since I pinpointed some buggy queries in our code, for an irrelevant model for our business. Something that was not cleaned up before, since nobody cared about this table. Second, I found a little bug in a double “for” loop.
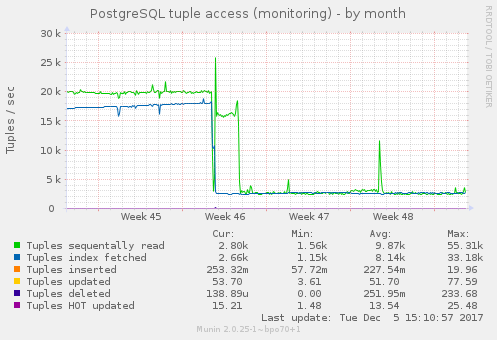
PostgreSQL now processes less data for the same results!
After that, I made some improvement on join related SQL queries that Django does not handle perfectly (e.g. the prefetch_related function generates large lists with the SQL “IN” operator). As you can seen in the picture, the results are pretty good for something that had already been optimized.
How easy is it in your experience to tweak Django queries when you know the SQL you want to write? How much of the Django facilities are still beneficial for you when doing “raw SQL”?
I always try it that way: I write the Python code using Django ORM as closely as possible to the expected result, and I compare that with my expected SQL query. Thanks to the extra() function, it’s then easy to add something to optimize or improve the request.
For example, the current Django version does not support filter on aggregation functions (like counts), and I recently added a custom “WHERE” to it (and I always write custom SQL queries in the manager class).
When Django releases this feature (probably for the next version), it will be easy to replace my custom query with the ORM feature.
Now that you have read the book in full, what’s your main take-out from it? Do you have a favorite part? What is the most useful thing that you have learnt in the book?
First of all, I appreciated a lot that this book is not a documentation copy and paste. This choice slows down the reading, since I had to have a look at many documentation references, but it keeps the book focused on valuables topics — the drawback is that the first chapter starts is a little bit fast.
I think that the main take-out is that now, I like SQL :-)
It gives me the motivation to solve problem at the database level, instead of the Python level. I’m more aware of what is possible with SQL. For example, I read the changelog of PostgreSQL 10, and I think that I understood the content. It’s a big improvement.
It’s hard to choose a favorite part, but I can say that I recognized some of our tables in the bad practice chapter. In one of our applications, we have a table mixing both key/value idea without type checking, and values sometimes stored in CSV like manner.
Read Mastering PostgreSQL in Application Development today and learn how to achieve tremendous resuls in production like Florent did!
To help you decide, here’s the Table of Contents of the whole book:
- Preface
- Introduction
- Some of the Code is Written in SQL
- A First Use Case
- Software Architecture
- Getting Ready to read this Book
- Writing Sql Queries
- Business Logic
- A Small Application
- The SQL REPL — An Interactive Setup
- SQL is Code
- Indexing Strategy
- An Interview with Yohann Gabory
- SQL Toolbox
- Get Some Data
- Structured Query Language
- Queries, DML, DDL, TCL, DCL
- Select, From, Where
- Order By, Limit, No Offset
- Group By, Having, With, Union All
- Understanding Nulls
- Understanding Window Functions
- Understanding Relations and Joins
- An Interview with Markus Winand
- Data Types
- Serialization and Deserialization
- Some Relational Theory
- PostgreSQL Data Types
- Denormalized Data Types
- PostgreSQL Extensions
- An interview with Grégoire Hubert
- Data Modeling
- Object Relational Mapping
- Tooling for Database Modeling
- Normalization
- Practical Use Case: Geonames
- Modelization Anti-Patterns
- Denormalization
- Not Only SQL
- An interview with Álvaro Hernández Tortosa
- Data Manipulation and Concurrency Control
- Another Small Application
- Insert, Update, Delete
- Isolation and Locking
- Computing and Caching in SQL
- Triggers
- Listen and Notify
- Batch Update, MoMA Collection
- An Interview with Kris Jenkins
- Closing Thoughts
