PostgreSQL HyperLogLog
If you’ve been following along at home the newer statistics developments,
you might have heard about this new
State of The Art Cardinality Estimation Algorithm called
HyperLogLog. This
technique is now available for PostgreSQL in the extension
postgresql-hll
available at
https://github.com/aggregateknowledge/postgresql-hll and soon
to be in
debian.
Table of Contents
Installing postgresql-hll
It’s as simple as
CREATE EXTENSION hll; really, even if to get there you
must have installed the
package on your system. We did some packaging work
for
debian and the result should appear soon in a distro near you.
Then you also need to keep your data in some table, straight from the documentation we can use that schema:
-- Create the destination table
CREATE TABLE daily_uniques (
DATE DATE UNIQUE,
users hll
);
Then to add some data for which you want to know the
cardinality of, it’s as
simple as in the following
UPDATE statement:
UPDATE daily_uniques
SET users = hll_add(users, hll_hash_text('123.123.123.123'))
WHERE date = current_date;
So in our example what you see is that we want to decipher how many unique
IP addresses we saw, and we do that by first creating a
hash of that source
data then calling
hll_add() with the current value and the hash result.
The current value must be initialized using
hll_empty().
Concurrency
The most awake readers among you have already spotted that: using an
UPDATE
on the same row over and over again is a good recipe to kill any form of
concurrency, so you don’t want to do that on your production setup unless
you don’t care about those
UPDATE waiting piling up in your system.
The idea is then to fill-in a queue of updates and asynchronously update the
daily_uniques table from that queue, possibly using the
hll_add_agg
aggregate that the extension provides, so that you do only one
update per
batch of values to process.
∅: Empty Set and NULL
Now, what happens when the batch of new unique values you want to update
from is itself empty? Well I would have expected
hll_add_agg over an empty
set to return an empty
hll value, the same as returned by
hll_empty(), but
it turns out it’s returning
NULL instead.
And then
hll_add(users, NULL) will happily return
NULL. So the next
UPDATE
is cancelling all the previous work, which is not nice. We had to cater for
that case explicitely in the
UPDATE query that’s working from the batch of
new values to add to our current
HyperLogLog hash entry, and I can’t resist
to show off one of the most awesome PostgreSQL features here:
writable CTE.
WITH hll(agg) AS (
SELECT hll_add_agg(hll_hash_text(value)) FROM new_batch
)
UPDATE daily_uniques
SET users = CASE WHEN hll.agg IS NULL THEN users
ELSE hll_union(users, hll.agg)
END
FROM hll
WHERE date = current_date;
That’s how you protect against an empty set being turned into a
NULL. I
think the real fix would need to be included in
postgresql-hll itself, in
making it so that the
hll_add_agg aggregate returns
hll_empty() on an empty
set, and I will report that bug (with that very article as the detailed
explanation of it).
Using postgresql-hll
When using
postgresql-hll on the production system, we were able to get some
good looking numbers from our
daily_uniques table:
with stats as (
select date, #users as daily, #hll_union_agg(users) over() as total
from daily_uniques
)
select date,
round(daily) as daily,
round((daily/total*100)::numeric, 2) as percent
from stats
order by date;
date | daily | percent
------------+--------+---------
2013-02-22 | 401677 | 25.19
2013-02-23 | 660187 | 41.41
2013-02-24 | 869980 | 54.56
2013-02-25 | 154996 | 9.72
(4 rows)
I coulnd’t resist to show off two of my favorite SQL constructs in that
example query here, which are the
Common Table Expressions (or CTE) and
window functions. If that
over() clause reads strange to you, take a minute
now and go read about it. Yes, do that now, we’re waiting.
The data here is showing that we did setup the facility in the middle of the first day, and that the morning’s activity is quite low.
Conclusion
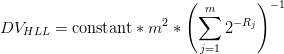
When using
postgresql-hll you need to be careful not to kill your
application concurrency abilities, and you need to protect yourself against
the ∅ killer too. The other thing to keep in mind is that the numbers you
get out of the
hll technique are estimates within a given
precision, and you
might want to read some more about what it means for your intended usage of
the feature.

