
Projects
How To Use PgLoader
This question about pgloader usage coms in quite frequently, and I think the examples README goes a long way in answering it. It’s not exactly a tutorial but is …
48 posts
This question about pgloader usage coms in quite frequently, and I think the examples README goes a long way in answering it. It’s not exactly a tutorial but is …
While currently too busy at work to deliver much Open Source contributions, let’s debunk an old habit of PostgreSQL extension authors. It’s all down to copy …
Following up on the very popular emacs-starter-kit, I’m now proposing the emacs-kicker. It’s about the .emacs file you’ve seen in older posts here, …
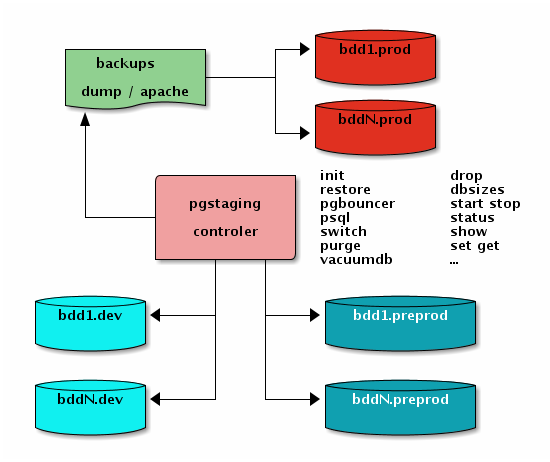
If you don’t remember about what pg_staging is all about, it’s a central console from where to control all your PostgreSQL databases. Typically you use it to …

It so happens that a colleague of mine wanted to start using Emacs but couldn’t get to it. He insists on having proper color themes in all applications and some …

After reading Simon’s blog post, I can’t help but try to give some details about what it is exactly that I’m working on. As he said, there are several …
It’s been a week since the last commits in the el-get repository, and those were all about fixing and adding recipes, and about notifications. Nothing like core …
I wanted to play with the idea of using the whole keyboard for my switch-window utility, but wondered how to get those keys in the right order and all. Finally found …
Thanks to you readers of Planet Emacsen taking the time to try those pieces of emacs lisp found in my blog, and also the time to comment on them, some bugs have been …
In trying to help an extension debian packaging effort, I’ve once again proposed to handle it. That’s because I now begin to know how to do it, as you can see …
Thanks to amazing readers of planet emacsen, two annoyances of switch-window.el have already been fixed! The first is that handling of C-g isn’t exactly an option …

So it’s Sunday and I’m thinking I’ll get into el-get sometime later. Now is the time to present dim-switch-window.el which implements a visual C-x o. I …