PostgreSQL is an all round impressive Relational DataBase Management System which implements the SQL standard (see the very useful reference page Comparison of different SQL implementations for details). PostgreSQL also provides with unique solutions in the database market and has been leading innovation for some years now. Still, there’s no support for Autonomous Transactions within the server itself. Let’s have a look at how to easily implement them with PL/Proxy.
In PostgreSQL we have pluggable languages: it’s possible to add support for programming languages to write your own stored procedures, and the core server ships with support for 5 such languages: PL/C, PL/SQL, PLpgSQL, PL/perl, PL/python and PL/tcl.
The PL/Proxy procedural language is not about providing an existing programming language. It’s about providing the user with remote procedure call and sharding facilities to spread any kind of laod in between a herd of PostgreSQL servers. It’s a very good Scaling Out solution, that we’re going to use for something quite different here.
Table of Contents
Remote Procedure Calls
Now, the main feature PL/proxy provides and that we’re going to benefit from today is the remote procedure call facility: when a function is called on a server, proxy it to another one, calling the same function with the same arguments over there, and fetching the result back. Classic proxying and RPC.
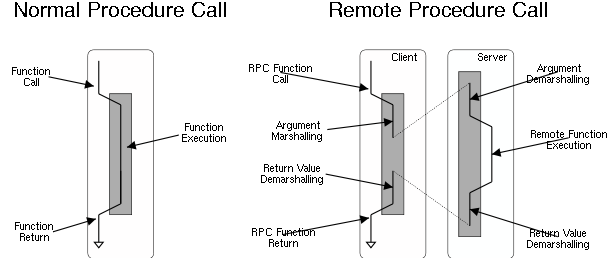
The main thing to understand with
PL/Proxy is that the remote procedure call
happens in its own transaction, when it returns it’s already been committed
on the remote server. So there’s no local control over the PL/Proxy
transaction, if you need to
ROLLBACK locally that’s too late.
Well, that limitation actually is a very interesting feature if what you want to obtain is an Autonomous Transaction, because it’s actually what it is. If you want the Autonomous Transaction to happen locally, all is needed is to connect the proxy back to the current database.
A practical Use Case: auditing trigger
Autonomous Transactions are useful when several units of processing need to
be done, and we want to be able to
COMMIT some of those without impacting
the main transaction’s ability to
ROLLBACK.
Note that with the
savepoint standard feature it’s possible to
ROLLBACK a
part of the processing while still issuing a
COMMIT for the overall
transaction, so if that’s what you need to do, you’re already covered with a
stock install of PostgreSQL.

Now, say you want to log any attempt to
UPDATE a row in that specific
critical table of yours, even if the transaction is then aborted. That’s
often referenced under the name
audit trigger and we already saw how to
implement such a trigger in our article
Auditing Changes with Hstore.
The whole goal of today’s exercise is going to populate our
audit table even
when the main transaction fails. Let’s first see what happens with the
solution we had already when we
ROLLBACK the main transaction:
> begin;
BEGIN
*> update example set f1 = 'b' where id = 1;
UPDATE 1
*> rollback;
ROLLBACK
> select * from audit;
change_date | before | after
-------------+--------+-------
(0 rows)
The auditing table is not populated.
Installing PLproxy
It begins as usual:
> create extension plproxy;
CREATE EXTENSION
For that command to work you need to have installed the Operating System
Package for plproxy (if using PostgreSQL 9.3 under debian you need to
install the
postgresql-9.3-plproxy package, as found in the
PostgreSQL debian repository). If you don’t have a package for
PL/Proxy you
need to fetch the sources from
https://github.com/markokr/plproxy-dev then
run
make install.
The Setup
Now that we have the extension, we need to use the CREATE SERVER command to have an entry point to a remote transaction on the same connection string.
> create server local foreign data wrapper plproxy options(p0 'dbname=dim');
CREATE SERVER
> create user mapping for public server local options(user 'dim');
CREATE USER MAPPING
> create function test_proxy(i int)
returns int
language plproxy
as $$
cluster 'local';
select i;
$$;
CREATE FUNCTION
> select test_proxy(1);
test_proxy
------------
1
(1 row)
Time: 0.866 ms
So we have a PL/proxy cluster to use, named local, and we tested it with a very simple function that just returns whatever integer we give it as argument. We can see that the overhead to reconnect locally is not daunting in our pretty simple example.

The remote auditing trigger
We already had a
trigger function named
audit that will work with the magic
variables
NEW and
OLD. What we want now is that the trigger function issues
a
remote procedure call to our
PL/proxy local connection instead:
create function audit_trigger()
returns trigger
language plpgsql
as $$
begin
perform audit_proxy(old, new);
return new;
end;
$$;
create function audit_proxy(old example, new example)
returns void
language plproxy
as $$
cluster 'local';
target audit;
$$;
create or replace function audit(old example, new example)
returns void
language SQL
as $$
INSERT INTO audit(before, after) SELECT hstore(old), hstore(new);
$$;
drop trigger if exists audit on example;
create trigger audit
after update on example
for each row -- defaults to FOR EACH STATEMENT!
execute procedure audit_trigger();
What you can see in that new setup is that the trigger calls the function
audit_trigger which in turns call the function
audit_proxy. That
proxy
function is the key for us to benefit from the
PL/proxy remote transaction
management, all the proxy function does is connect back to
localhost then
call the function named
audit with the same parameter it got called with.
The previous example was made quite generic thanks to using hstore. We can’t use pseudo types with PL/proxy so we need a pair of functions per table we want to be able to audit in this fashion.
Now here’s what happens with those definitions and an aborted
UPDATE:
> begin;
BEGIN
*> update example set f1 = 'b' where id = 1;
UPDATE 1
*> rollback;
ROLLBACK
> select change_date,
before, after,
after-before as diff
from audit;
-[ RECORD 1 ]--------------------------------
change_date | 2013-10-14 14:29:09.685105+02
before | "f1"=>"a", "f2"=>"a", "id"=>"1"
after | "f1"=>"b", "f2"=>"a", "id"=>"1"
diff | "f1"=>"b"
The aborted update has been captured in the audit logs!
Conclusion
Thanks to a design where extensibility is a first class citizen, PostgreSQL makes it possible to implement Autonomous Transactions without having to edit its source code. Here we’re using a special kind of a Foreign Data Wrapper: the PL/proxy driver allows implementing remote procedure calls and sharding.
If you need Autonomous Transactions and though PostgreSQL might not be suitable in your case, now is the time to review your choice!

